

Rapporten fra Nordic Safe Cities (NSC), for øvrig en tenketank som ble initiert under Nordisk Ministerråd i 2016 etter et de islamistiske terrorangrepene i København på et seminar om ytringsfrihet og en synagoge, har ved hjelp av kunstig intelligens gått gjennom i underkant av 10,5 millioner kommentarer på Facebook i perioden 1. januar 2020 til og med 17. september 2022.
Hovedfunnene er at 1,7 prosent av disse kan kategoriseres som «språklige angrep» og av dette igjen er 0,4 prosent kategorisert som «hatprat». Jubelen burde stå i taket, tenke seg til at i en tid der altfor mange blir krenket og såret av altfor mye, så er altså 99,6 prosent av kommentarene ikke definert som hatprat, mens bare 1,7 prosent er definert som språklige angrep. Samtidig blir det jo en del kommentarer da utvalget er så stort, til sammen 177.077 kommentarer av totalt ca. 10,5 millioner kommentar.
Men, kan vi stole på denne rapporten? La oss se ta en titt på den metodiske delen.
Definisjoner og tolkninger
NSC-rapporten vier mye av plassen på den metodiske innfallsvinkelen. Det gjelder for det første definisjonen av ulike begreper:
- Språklige angrep: Stigmatiserende, nedsettende, krenkende, stereotypiserende, ekskluderende, sjikanerende eller truende ytringer.
- Hatprat – underkategori av språklige angrep: Et språklig angrep mot en gruppe eller et individ basert på gruppens eller individets beskyttede karakteristika. (De benytter en definisjon som er bredere enn den juridiske definisjonen av «hatefulle ytringer», jmf. § 185 i straffeloven).
«Beskyttende karakteristika» er definert til rase/etnisitet, hudfarge, nasjonalitet og opprinnelse, religion og tro, seksuell orientering, kjønn og kjønnsidentitet, sosial klasse og sosial status, politisk orientering, alder eller funksjonshemming og alvorlige sykdommer (både fysiske og psykiske), mens «ikke-beskyttende karakteristika» er for eksempel yrke, utdanning, lokal geografisk tilhørighet og lignende.
De gir selv noen eksempler på hva de ser på som angrep og ikke-angrep, og merk at konteksten kommentaren faller i er uten betydning:
- «Muslimer burde ikke ha stemmerett i noen europeiske land.»
- «Send dem ut av Norge.»
- «<Navn> var du der?? For en idiotisk kommentar!!.»
- «Hun derre helvetes kjerringa altså… måtte du få champagne korken mitt mellom øgene ditt brødnaut.»
Klarer du gjette hvem av disse fire tilfeldig valgte kommentarene som er angrep versus ikke-angrep?
Vi kan avsløre at 1) og 4) anses som angrep, mens 2) og 3) ikke er det. Forståelig? Ikke her på bruket, selv etter at NCS «forklarer». For 1) er et angrep fordi det uttrykker at noen burde ekskluderes og fratas grunnleggende rettigheter. Vi anser det som en meningsytring, som en kan være enig eller uenige i. 2) er ikke et angrep fordi det representerer en legitim holdningsytring, om enn kontroversiell, heter det. I vår tolkning er det eneste som skiller 1) og 2) bruken av ordet «muslimer». 3) er heller ikke et angrep fordi – til tross for at en person er navngitt – da det er kommentaren, ikke mennesker, som blir angrepet. Vel, det er jo også en tolkning, er vårt svar. Det som gjør 4) til et angrep er at det er bruk av nedsettende ord om beskyttende karakteristika, her kjønn og alder, altså «kjerringa» (som de implisitt tolker til å være ei gammel kjerring). Vi antar at i alle fall hele Nord-Norge ler seg skakk.
Så er det skillet mellom språklige angrep og hatprat:
- «Spyrrrr av hele kvinnfolket, kvalmende..»
- «Forbanna pisspreik! Muslimene hater homofile, men elsker å voldta barn, og da bryr de seg ikke om hvilket kjønn det er!»
- «<Navn>, …og du er blodrød kommunist, full av løgn! Lavere er det ikke mulig å synke!»
- «<Navn> Stygge troll!»
Nå antar vi at du, slik som det er med kunstig intelligens, har lært litt av eksemplene over, så klarer du?
Fasiten er: 1) er hatprat. «Kvinnfolket» er angrep på kjønn (så nå ler hele vestlandet seg skakk). 2) er hatprat fordi det er et angrep basert på nedsettende og stereotypiserende innhold med hensyn til religion og tro. Til det er det bare å poengtere at NSC åpenbart ikke har vært innom noen muslimske sider på Facebook, og vi registrerer jo fraværet av andre tro og religioner. 3) er hatprat, fordi det er et angrep på politisk orientering. Da er altså 4), til tross for navngivelse også her, «bare» et språklige angrep. Stygge troll er nemlig ikke en beskyttende karakteristikk.
Epler og pærer
Så var det det der med å sammenlikne epler og pærer – og ende opp med fruktsalat. For det er begått en sammenblanding som ikke kan karakteriseres som annet enn en grov metodefeil i rapporten.
Vi leser følgende:
Andelen språklige angrep er høyest blant debattantene, da fire av ti i figuren til høyre faller inn i denne kategorien. Særlig Hege Storhaug skiller seg ut, og hele 5,5 prosent av alle kommentarene på Facebook-siden hennes inneholder språklige angrep. Blant de offentlige personene finner vi suverent flest angrepskommentarer på hennes side. Utover de fire debattantene finner vi tre kulturpersonligheter, to idrettsutøvere og én interesserepresentant på topp 10-listen, men ingen influensere.
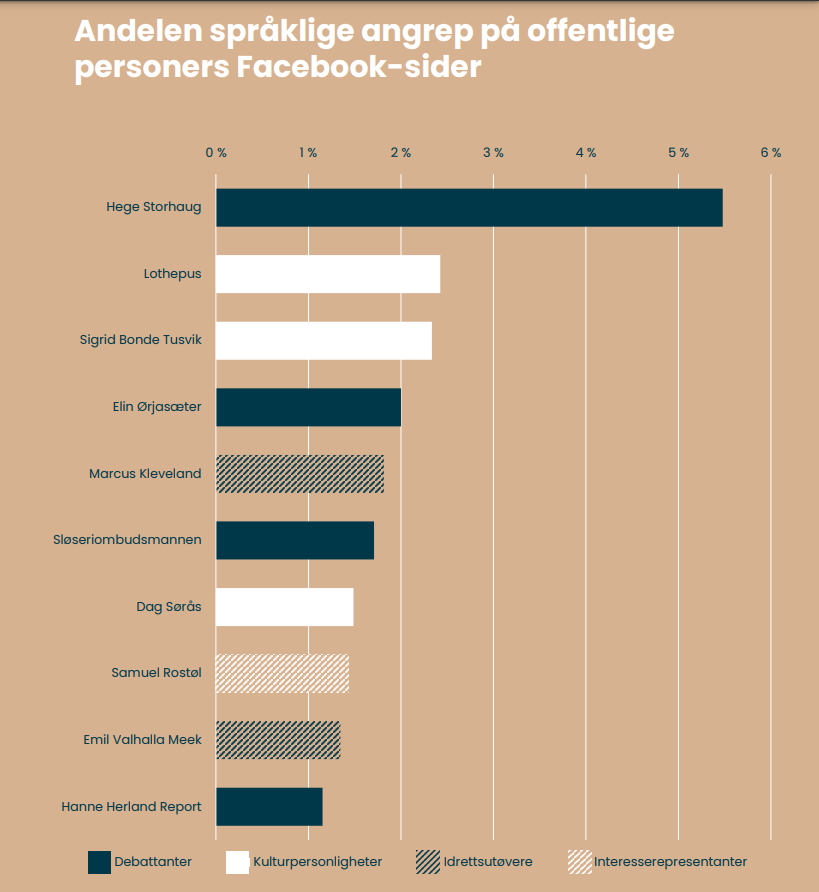
Dette er altså «verstingene», men det rapportskriverne «glemmer» å nevne er at det bare er Hege Storhaug og Sløseriombudsmannen som bruker fb-sidene sine utelukkende til debattinnlegg. De andre bruker dem til private innlegg i tillegg. Dermed blir prosentfunnene ganske pussige, all den tid NSC ikke har plukket vekk private innlegg, men sett på totalen.
Hadde Hege Storhaug pumpet ut valpebilder og pene blomsterbilder i samme tempo som andre legger ut private bilder som genererer forutsigbart mange kommentarer, ville naturlig nok prosentandelen av hatkommentarer gått drastisk ned.
Det du putter inn, får du ut
Kunstig intelligens er på agendaen om dagen, og det er ikke det minste merkelig. Det er teknologi i rivende utvikling og de store tek-gigantene slåss om å være størst og best. I tillegg har vi nylig skjønt at våre egne hemmelige tjenester, her PST, vil ta i bruk kunstig intelligens i masseovervåkning av borgerne. Det er all grunn til å være både kritisk og på vakt over det som foregår.
Etter å ha sett noen eksempler på hvordan NSC definerer og tolker begynner man jo å ane hvor veien bærer hen. Dit de vil, for å si det slik. Og stikkordet her er «de», for det er mennesker som mater «trollet» og da kommer det ut det du putter inn. I dette tilfellet er det seks mennesker – som vi selvsagt ikke får vite hvem er – som er gitt mesteparten av definisjonsmakten (i tillegg til en kodemanual, også utarbeidet av mennesker). Disse seks menneskene kalles annotører, da de markerer relevant informasjon i tekst som brukes til trening av en språkmodell. Det fremkommer for øvrig at dette prosjektets annotører er Johanne Ringøen og Vemund Wik (aner ikke hvem de er), men hva som ligger i den informasjonen er vanskelig å si. Har disse to «styrt» dette prosjektet? For det heter videre:
I vårt prosjekt har seks annotører kategorisert i alt ~137 000 kommentarer (~70 000 norske og ~67 000 danske) og avgjort om de inneholder angrep eller ei. De annoterte kommentarene utgjør algoritmens trenings- og testdata. 5 prosent av kommentarene er blitt kategorisert av mer enn én annotør. Disse kommentarene brukes til å regne ut en score for annotørenes innbyrdes enighet.
NSC har selv angitt en punktsliste over prosessen, som noe kortfattet ser slik ut:
- Mennesker utarbeider en definisjon av språklige angrep og hatprat (jamfør over).
- Mennesker utarbeider en kodemanual til annotører med regler for, og eksempler på, hvordan man gjenkjenner språklige angrep.
- Menneskers (annotørenes) rolle.
- Mennesker designer en enkel algoritme bestående av en forhåndstrent skandinavisk språkmodell og en klassifiseringsmodul. Algoritmen har en god forståelse av skandinaviske språk, men kan ennå ikke identifisere språklige angrep.
- Algoritmen gis størstedelen (noen spares som testdata til senere) av de annoterte kommentarene (altså forbehandlet av mennesker) og begynner å gjenkjenne regler og mønstre for når en kommentar skal klassifiseres som angrep eller ikke.
- Den foreløpige algoritmen testes på en input av kommentarer. Algoritmen returnerer kommentarene med sin vurdering av om kommentarene inneholder et angrep.
- Mennesker, eller annotørene «etterannoterer» både kommentarene som algoritmen er sikker på, og kommentarene den er i tvil om. De forteller algoritmen i hvilke tilfeller den har rett, og i hvilke tilfeller den tar feil.
- Algoritmen får kommentarene i retur med den menneskelige inputen og settes nok en gang til å gjenkjenne mønstre og regler for når en kommentar inneholder et angrep. På den måten korrigeres algoritmens forståelse. Denne formen for gjentakende trening kalles aktiv læring.
- Vi eksperimenterer med best mulig inputdata til algoritmen. Algoritmen ble for eksempel ikke bedre av å kjenne konteksten til kommentarene, det vil si navnet på Facebook-siden og Facebook-innlegget der kommentaren forekom. Til gjengjeld kjenner algoritmen igjen emojier, og de inngår i algoritmens regler.
- Algoritmen trenes og justeres frem til den oppnår best mulig resultater på et testdatasett (de sparte, annoterte kommentarene). Gjennom treningen forsøker vi å forbedre to kvaliteter hos algoritmen: presisjon og tilbakekalling.
Man skal være rimelig naiv om man ikke skjønner at dette er svært aktøravhengig, og man blir ikke veldig overrasket over hva denne algoritmen har lært når vi ser på prosjektets referansegruppe:
- Eirik Rise, Kampanjerådgiver, Stopp Hatprat
- Eliana Hercz, Koordinator, Dialogpiloterne
- Elin Solberg, Fagdirektør, Justis- og beredskapsdepartementet
- Elsa Skjong-Arnestad, Leder Rosa kompetanse justis, FRI
- Erik Velldal, Professor ved Informatikk, UiO
- Hatem Ben Mansours, Nestleder, Antirasistisk Senter
- Jørgen Frydnes, Daglig Leder, Utøya
- Lars M. Gudmundson, Leder, Hegnhuset – læringssenteret på Utøya
- Lilja Øvrelid, Professor ved Informatikk, UiO
- Linda Tinuke Strandmyr, Daglig Leder, Antirasistisk Senter
- Marjan Nadim, Professor og forsker, Norsk Senter for Samfunnsforsking
- Mikkel Berg-Nordlie, Forsker & Forfatter, OsloMet
- Monica Lillebakken, Leder hatkrimgruppa, Oslopolitiet
- Monika Kochowicz, Prosjektleder, Stopp Hatprat
- Stian Lid, Forsker, By- og regionsforskningsinstituttet NIBR, OsloMet
- Tore Bjørgo, Leder, Senter for ekstremismeforskning, C-REX (Bjørgo er for øvrig også «Safe City»-rådgiver)
«Hele debatten»?
Så en annen ting: NSC skryter av at de fanger «hele debatten».
Med den nye algoritmen har vi – som de første – kunnet undersøke hele debatten i Norge, og dermed har vi også bidratt til forskningen på debattklimaet på Facebook. ( … )
Undersøkelser som er basert på stordata, gir oss et helt annet innblikk i den offentlige debatten enn hva spørreundersøkelser eller strukturerte intervjuer kan gi. Ved å undersøke Facebook-debatten kan vi se på langt større datamengder enn vi noensinne vil kunne gjøre med mer konvensjonelle metoder. I stedet for et tilfeldig utvalg av innlegg og kommentarer kan vi nå undersøke hele debatten.
Men de ligger langt lavere med at det er de selv som har valgt ut hvilke offentlige Facebook-sider som underlegges en slik undersøkelse:
… for første gang i Norge brukt maskinlæring til å kvantifisere hele debatten som finner sted på et stort antall offentlige Facebook-sider, nærmere bestemt Facebook-sidene til norske politikere, offentlige personer, medier og offentlige debattsider. Dette er sider hvor det deles nyheter, holdninger og standpunkt i stor skala, og hvor Facebook-brukere kan kommentere.
Siden Hege Storhaugs Facebook-side, hun omtales forresten som «forfatteren, redaktøren og debattanten», men redaktør har hun aldri vært, er plukket ut, sier det sitt. Storhaug er islamkritiker, hun publiserer mye om islam, og da sier det seg selv at – gitt NSC’ definisjoner – det vil gi utslag. Noen som lar seg overraske?
Da kan vi vel bare takke igjen for en rapport og medieoppslag (TV2: Hets på nett er ødeleggende for det norske demokratiet og NRK: Hets og hat på nett: – Det går på friheten vår) som kanskje mest av alt lurer oss trill rundt.
Nordic Safe Cities: Angrep og hat i den offentlige debatten på Facebook